Une chaîne de publication est un ensemble de méthodes et d’outils ordonnés qui remplissent des objectifs déterminés pour un projet éditorial. De la gestion d’un texte à la production d’un objet physique ou numérique, en passant par les phases de structuration, de relecture et de composition, la publication est un processus complexe constitué d’intervenants divers. Comme nous l’avons vu dans la partie 2, les initiatives originales pour concevoir, fabriquer et produire des livres existent et fonctionnent. Avant d’envisager un modèle basé sur ces initiatives, nous devons analyser et comprendre comment les chaînes d’édition dites classiques sont organisées. Au-delà de ces fonctionnements établis et observables, il nous faut extraire des pratiques actuelles les différentes étapes de publication. Nous pouvons supposer que ces étapes, extraites des procédés et des techniques, constituent un socle générique et relativement indépendant des méthodes adoptées.
L’écriture représente la colonne vertébrale d’une démarche éditoriale, mais qu’est-ce qui constitue cette étape ? Quels en sont les logiciels et les modes d’édition ? La gestion des documents est ici essentielle, elle offre un cadre pour les révisions d’un texte et pour les collaborations autour de celui-ci. Comment celle-ci est-elle actuellement établie ? La mise en forme d’un document est l’interprétation de sa structure et l’attribution de styles. Le rendu graphique est essentiel pour appréhender un texte, pour donner vie aux contenus, mais quelles sont les principales contraintes rencontrées à ce niveau par les acteurs d’un projet d’édition ? Enfin, l’acte de publication est la mise à disposition d’un livre, l’enjeu est donc d’en définir les formes, et les conditions de production de celles-ci. Un livre numérique peut-il être conçu de la même façon qu’un livre imprimé ?
L’analyse de ces phases d’édition doit prendre en compte la façon dont elles s’articulent : quelles relations existe-t-il entre deux étapes qui se succèdent ? Et surtout est-il possible de déstructurer l’ordre de ces étapes pour former un ensemble plus cohérent ? Le concept de chaîne doit-il être remis en question ?
3.1.1. Écrire et structurer
L’écriture est la première des étapes de production d’un livre, mais elle constitue aussi le fil rouge de l’activité de publication. Qu’il s’agisse de l’inscription d’une idée – le point de départ –, ou des dernières corrections avant l’impression finale, le texte est continuellement travaillé. L’écriture peut être décomposée en deux actions distinctes et complémentaires : inscrire et structurer. Inscrire pour fixer des contenus. Structurer pour distinguer les éléments qui constituent ces contenus. Les outils d’écriture permettent de réaliser ces deux opérations, imposant bien souvent une approche particulière dans leur réalisation et leur compréhension.
L’inscription d’un texte est probablement l’action la plus intégrée et la plus inconsciente de l’écriture. Et ce d’autant plus depuis la numérisation des outils de rédaction – aujourd’hui représentée par le traitement de texte, de Microsoft Word à LibreOffice Writer en passant par Pages. L’écriture manuscrite matérialise cette étape d’inscription : l’encre imprègne le papier, chaque lettre et chaque mot marquent le support physique. L’image de l’épigramme est probablement encore plus évocatrice, l’inscription étant gravure, et difficilement modifiable ou effaçable. Désormais ce sont les touches d’un clavier enfoncées ou l’effleurement d’un écran qui signifie cette inscription, ainsi que les fonctions d’enregistrement des logiciels et applications.
La structuration est une démarche à la fois plus visible et moins compréhensible dans l’acte d’écriture. Plus visible car elle revêt des caractères graphiques. Moins compréhensible car elle se limite bien souvent à cette seule dimension de mise en forme. La structuration d’un texte est la distinction des éléments qui le composent. Un texte n’est pas constitué de lettres et de mots au kilomètre, mais chaque fragment a une caractéristique propre : un titre, un paragraphe, une liste, une citation, une note, etc. Autant de composants qui constituent un ensemble logique, qui s’organisent pour donner sens. Autant de fragments, donc, qui portent des significations différentes, en dehors du contenu lui-même : le titre nomme un texte, un paragraphe développe une idée, une liste énumère avec ou sans ordre, une citation signale l’apport d’un autre texte, une note précise un point particulier, etc.
La question de la structuration est trop souvent éludée dans les pratiques d’écriture, qu’elles soient techniques, académiques ou même fictionnelles. Les textes portent alors des significations grâce à des artifices graphiques : un titre a une taille de police plus importante, une citation est mise en italique. Ces simulations visuelles limitent les compréhensions hors contexte – comme la suppression de cette mise en forme –, ou freinent les manipulations par des programmes – pour transformer un fichier dans des formats spécifiques par exemple.
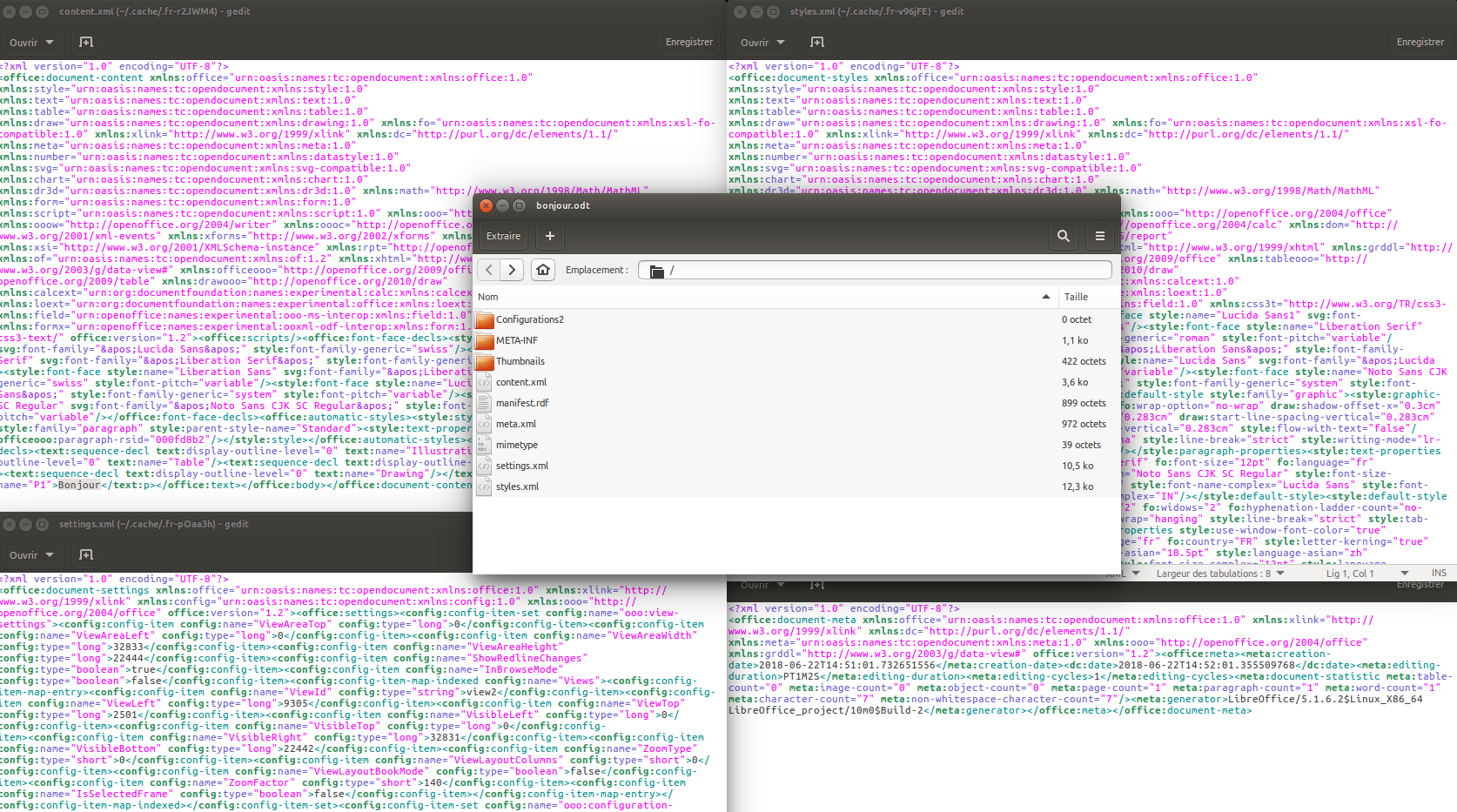
Le traitement de texte est l’outil le plus utilisé pour inscrire et structurer du texte, et pourtant il conduit à un certain nombre de confusions. La première d’entre elles est la visualisation, en direct, du rendu de la mise en forme. L’utilisateur peut voir, sans attendre un quelconque processus, les styles appliqués au texte : un changement de police pour un titre ou une mise en italique d’un passage. Cette fonctionnalité est particulièrement utile pour relire un texte avec ces précieuses informations. Mais bien souvent l’intervention de l’utilisateur se limite à une application graphique sans indiquer la structure qui signifie cette mise en forme. Ensuite, si une structuration est attribuée, seul le logiciel peut la comprendre et l’interpréter. En effet dans le cas d’un traitement de texte une information concernant un niveau de titre est traduite dans un langage informatique complexe comme le XML. Ouvrir un fichier au format .docx peut s’avérer étonnant voir angoissant de complexité, quand bien même ce fichier ne comporte qu’un mot :
You can see this hidden world by creating a Pages or Word document, typing « Hello World » and saving, then changing the extension to .zip and unzipping the file. Welcome to 1979! If you are courageous enough to look inside the resulting folder, you may start wondering whether you typed « Hello World » or « Hello Hell ».
(Reichenstein, 2016).
D’un côté l’utilisateur ne sait pas forcément qu’il met en forme sans structurer, de l’autre le logiciel est le seul à comprendre parfaitement les informations de structuration.
Dans le domaine de « l’écriture scientifique » (Guichard, 2008), les pratiques liées à la structuration des contenus sont trop souvent pauvres ou réduites à des logiciels propriétaires et fermés. Le passage de l’imprimé au numérique, en ce qui concerne l’écriture, doit se faire par une maîtrise de techniques et d’outils par les chercheurs, universitaires ou enseignants eux-mêmes. « Savoir écrire est une compétence technique indispensable pour tout chercheur ou auteur en sciences humaines et sociales. » (Vitali-Rosati, 2018) Cette « compétence technique » ne doit pas être déléguée.
Le traitement de texte utilise un « mode d’édition » (Têtue, 2014) appelé WYSIWYG, pour What You See Is What You Get – ou ce que vous voyez est ce que vous obtenez, en français. Le sens n’est donc pas ici la priorité, mais plutôt le rendu graphique, l’aperçu. Le principe du WYSIWYG est également utilisé dans de nombreuses applications web, comme des systèmes de gestion de contenu permettant d’éditer des sites web ou des blogs – ou CMS pour Content Management System. Écrire avec une interface en WYSIWYG apporte nécessairement une confusion entre la structure et sa mise en forme, puisque la personne qui saisit du texte dispose d’options prioritairement visuelles. Le manque de structuration des textes n’est pas du fait des utilisateurs mais plutôt des interfaces qui leur sont proposées. Nous pouvons tout de même mentionner l’effort de certains éditeurs WYSIWYG qui proposent des options sémantiques, le problème de ces dernières étant de ne pas correspondre exactement au rendu final, créant là une certaine frustration (Schrijver, 2017). Une approche alternative, basée sur le sens, est celle du WYSIWYM, pour What You See Is What You Mean. La distinction entre le contenu et la forme est alors affirmée, et l’utilisateur comprend ce que structurer veut dire : c’est le sens même du langage HTML et de son corollaire le langage CSS.
Nouvel objet de l’ère informatique, le texte « souple » est séparé de toute représentation typographique, introduisant ainsi la notion de « flux » de texte. Il peut être représenté d’une infinité de manières, au gré des copier-coller dans de nouveaux contextes, de l’email au traitement de texte. C’est une idée fondamentale, que l’on retrouve par exemple aujourd’hui dans les pages Web, puisqu’elles sont composées à partir de deux langages distincts : les données structurées (HTML) et l’ensemble de règles qui vont venir mettre en forme ces données (CSS).
(Maudet, 2017)
Les langages de balisage léger Markdown et AsciiDoc sont une application possible du mode d’édition WYSIWYM : la structure est signalée à l’aide de quelques balises plutôt que par des éléments graphiques.
Quelques exemples pour Markdown : dans un document un titre de niveau 3 est signalé par trois dièses, ### Titre ; un passage en emphase en italique est entouré par des tirets ou des étoiles, _italique_ ; une citation est indiquée par un chevron, >Une citation.
Une autre confusion induite par les traitements de texte est la sensation de compatibilité. Aujourd’hui tous les ordinateurs sont pourvus de logiciels capables d’interpréter du .docx ou du .odt, ou en tout cas il est relativement simple d’installer des logiciels permettant cette interprétation. En tant qu’utilisateur nous n’avons pas conscience que ces fichiers ne sont lisibles facilement que dans un contexte précis et pour un temps limité. Tout d’abord selon le niveau de complexité d’un document Microsoft Word ou LibreOffice Writer, celui-ci ne s’affichera pas de la même façon selon qu’il a été créé avec Word ou LibreOffice – nous avons tous connu des mésaventures à ce sujet. Ensuite en fonction des évolutions des logiciels et des formats, il est fort probable qu’un fichier .docx de 2018 ne soit plus lisible en 2028, ou que des informations soient perdues ou difficilement extractible. Enfin, dans le cas où nous souhaiterions utiliser un autre type de logiciel, par exemple un outil de mise en page plus avancé, il y aura un problème de compatibilité : le nouveau logiciel n’est pas en mesure de prendre en compte toutes les propriétés du précédent. Dans les domaines de l’édition technique, de la publication universitaire ou plus globalement de la non-fiction, l’interopérabilité est une nécessité. En tant qu’utilisateur nous devons comprendre que le texte que nous inscrivons a également une structure. Et nous devons pouvoir intervenir sur celle-ci. Nos pratiques d’écriture ne doivent pas être dictées par des logiciels :
Les traitements de texte développent cette pensée à partir de présupposés implicites qui apparaissent comme autant d’enthymèmes. En utilisant un traitement de texte, nous admettons un certain nombre de leurs prémisses.
(Dehut, 2018)
Écrire, en tant qu’étape d’un processus de publication, est donc contraint par les outils que nous utilisons, mais aussi indirectement par les modes d’édition de ces outils. Si le besoin d’interface est indéniable pour faciliter l’édition de contenus, celui de revenir au texte l’est également (Fauchié & Parisot, s. d.), pour mieux saisir les enjeux sémantiques des documents, des publications et des livres. Les traitements de texte, auxquels nous souhaitons ici trouver des alternatives, portent également des promesses de collaboration, en plus de l’écriture au sens d’inscription et de structuration comme nous venons de l’exposer. Nous allons désormais explorer ces fonctions de partage, de collaboration et de validation des textes.
3.1.2. Partager, collaborer et valider
L’écriture n’est pas seulement une étape dans un processus d’édition, mais une action qui se répète pendant toute la chaîne de publication : inscription, structuration, mais aussi correction et validation sont autant de phases qui se suivent et se superposent. Pour permettre à différentes personnes d’intervenir sur un texte, et ce à plusieurs reprises, divers moyens sont mis en œuvre. De la numérotation à un procédé basé sur les versions, des outils bureautiques fermés aux plates-formes prétendument faciles d’utilisation, nous étudions les différentes façons de travailler sur un texte.
Dans un environnement numérique, revenir sur un texte nécessite tout d’abord de le nommer.
Deux méthodes sont communément utilisées pour faire apparaître cette information dans le nom du fichier informatique : la numérotation incrémentale – chaque nouvelle version est désignée avec un chiffre supérieur à la précédente – ou la date d’édition.
Les deux peuvent également être mixées.
Il est fréquent de travailler avec des fichiers tel que chapitre-01-v14-2017-06-17.doc, voir même chapitre-01-v14-relecture-antoine-2017-06-17.doc, car il ne s’agit pas de prendre en compte uniquement les versions successives d’un même auteur ou d’un même relecteur, mais d’identifier en plus les actions sur le texte.
Ici antoine est probablement un relecteur comme en atteste la mention relecture.
Nous pouvons donc identifier trois informations distinctes :
- le numéro de la version ;
- l’action sur le texte ;
- la personne qui est intervenue sur le fichier.
Vient ensuite la question de l’échange et du partage des fichiers. Comment mettre à disposition un texte pour qu’un correcteur le relise, ou qu’un éditeur le valide ? Si les intervenants d’un projet éditorial – qu’il s’agisse d’un essai, d’un roman ou plus globalement d’un document – sont réunis dans un même espace physique, des solutions de mise en réseau existent : Intranet, serveur partagé ou NAS. Dans le cas où les personnes sont éloignées, des outils de partage de documents peuvent être utilisés, comme le très populaire Dropbox. Enfin des dispositifs d’édition en ligne sont utilisées de plus en plus massivement, le cas de Google Drive est emblématique. Pourtant la messagerie électronique semble être le choix par défaut : les fichiers s’échangent par messages successifs, plutôt que d’être mis en commun. Cela peut s’expliquer assez facilement : le mail est, avec les outils bureautiques comme le traitement de texte, l’un des instruments les plus répandus. Et le travail à distance avec l’usage de terminaux informatiques nomades – comme l’ordinateur portable – obligent à ne pas dépendre d’une infrastructure uniquement locale. Si cette méthode de la numérotation successive et de l’échange par courrier électronique est compréhensible par toutes et tous – et notamment par des auteurs qui ne sont pas des techniciens de l’édition –, elle pose un certain nombre de problèmes. Chaque nouvelle version écrase la précédente (Fauchié, 2018), et la gestion des messages successifs devient rapidement complexe à gérer : toutes les remarques sont dispersées dans des mails et dans des fichiers éclatés.
Comme évoqué ci-dessus, des solutions d’édition en ligne existent, et semblent résoudre cette difficulté d’administration des versions. Que ce soit un pad ou un document Google Docs, les modes de fonctionnement de cette – relative – nouvelle approche sont divers. Par ailleurs ces deux exemples sont représentatifs de ce que l’on appelle l’informatique dans les nuages (Figer, 2009) : plus besoin d’installer un logiciel sur son poste informatique, l’accès se fait directement en ligne. En plus de Drive – outil de synchronisation de fichiers –, Google propose des outils bureautiques en ligne sous l’appellation Google Docs, utilisables avec un simple navigateur web. L’édition simultanée à plusieurs est possible, comprenant des fonctionnalités de commentaires et de versionnement basiques. Si la bureautique en ligne semble pertinente pour résoudre les problèmes liés à l’édition à plusieurs, elle présente plusieurs limites :
- la structuration est possible, comme avec un traitement de texte, mais avec un périmètre réduit. De la même façon la mise en forme – et donc les feuilles de style – n’ont pas d’options très avancées ;
- ces plates-formes sont des silos hermétiques : l’accès et les sauvegardes dépendent de Google et de ses infrastructures. Les discontinuités de service sont rares mais présentent un risque non négligeable de rupture de chaîne ou de perte de documents ;
- le mode d’édition est en WYSIWYG, avec les contraintes exposées plus haut dans la partie 3.1.1.
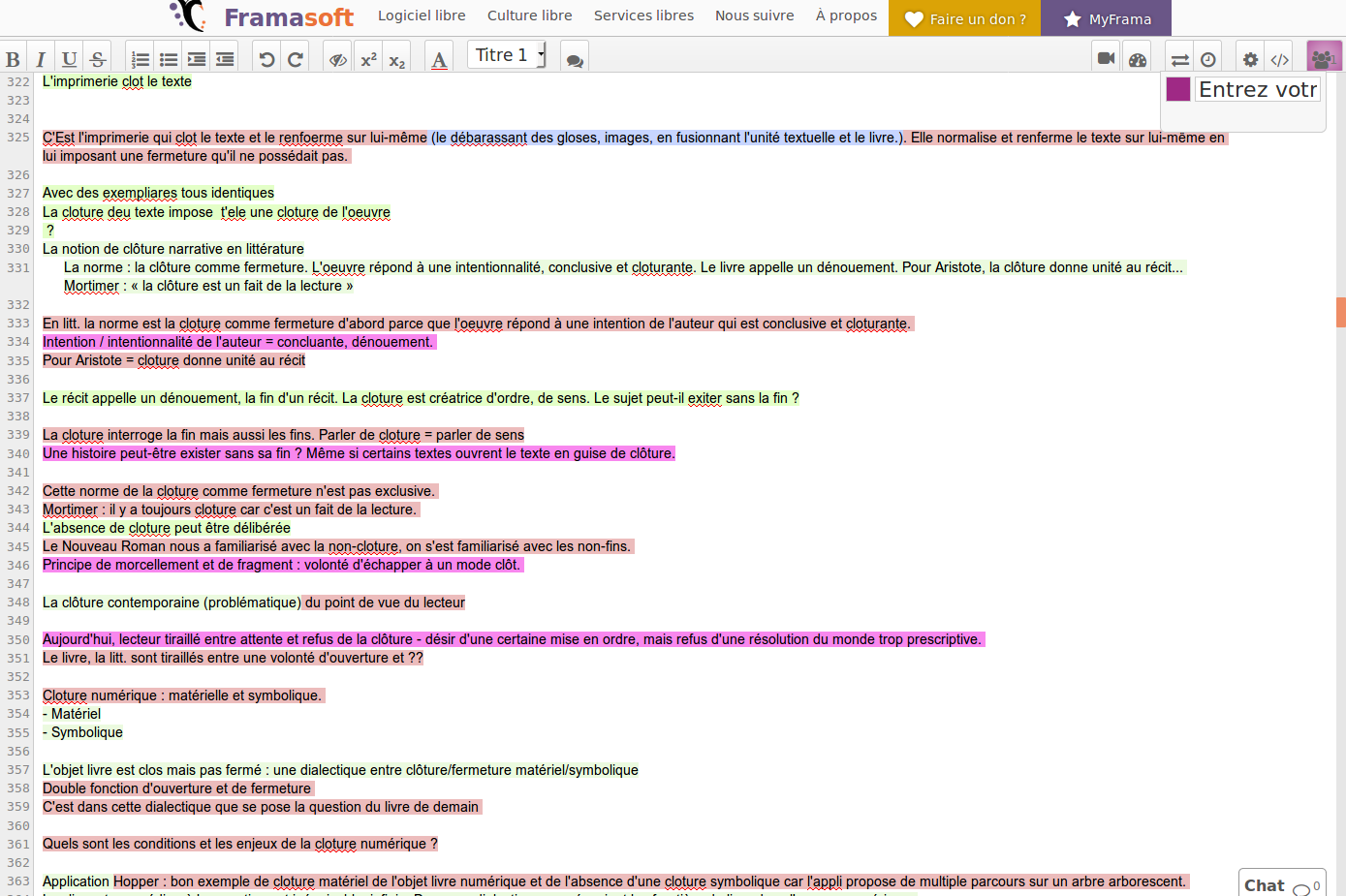
Le pad est un éditeur de texte collaboratif en ligne1, où chaque modification est visible en direct. Les interventions des utilisateurs sont différenciées par des couleurs, ce qui donne des résultats visuellement étonnants – une même phrase pouvant être littéralement et graphiquement multicolore en raison du nombre de modifications. Les options de structuration et de mise en forme sont relativement limitées, mais des fonctions d’export existent dans divers formats. Le pad n’est pas tout à fait un WYSIWYG, dans le sens où le style ne peut pas être modifié – pour le dire autrement il n’y a qu’une façon de voir la structuration, contrairement à un traitement de texte. Le pad est un outil souvent utilisé dans des phases d’amorçage d’un projet d’écriture, il permet de réunir des contributions, mais sa simplicité freine des usages plus avancés : relectures, annotations, mise en forme, etc.
L’indication de la version, de l’intervenant et de l’action, mais également la mise à disposition du texte et la réunion des différentes interventions paraissent complexes à contrôler. Un système de gestion de versions, offrant la possibilité d’identifier les intervenants et les interventions, de fusionner ces dernières, et de se connecter à des outils d’écriture, serait là une solution. Mais avant d’envisager de telles alternatives, examinons la prochaine étape d’édition qui consiste en la mise en forme d’un texte.
3.1.3. Mettre en forme
Inscrire, structurer, collaborer, corriger, valider, autant d’actions qui concernent le texte et sa structure sans pour autant prendre en compte la forme de celui-ci – hormis des aperçus transitoires. La mise en forme d’un document est en soi une étape dans le processus de publication, elle intervient classiquement après les phases de relecture et d’amendement d’un texte. Elle favorise la compréhension de celui-ci, elle guide l’utilisateur dans sa lecture. Pourtant elle est encore trop souvent l’objet d’une confusion avec le contenu, et aujourd’hui elle rencontre des difficultés pour s’adapter aux nombreuses formes que peut prendre le livre.
La mise en forme prolonge l’agencement de la structure du texte, elle est plus spécifiquement l’habillement du livre (Tschichold & Paris, 2011). Chaque élément est qualifié lors de la phase de structuration : un titre, un paragraphe, une liste, une citation, etc. À cette information qualifiée nous pouvons ensuite attribuer un style : pour un titre de niveau deux un ensemble de caractéristiques graphiques sont données, comme la police de caractère typographique, la taille de cette police, la couleur du texte, l’alignement, etc. Ces spécificités visuelles doivent traduire le sens porté par la structure, et parfois une hiérarchie dans l’ordonnancement des contenus : un titre est mis en avant d’une façon plus conséquente qu’un paragraphe par exemple. C’est là toute la force d’une séparation distincte entre la structure et la mise en forme, cette dernière peut être modifiée à loisir sans avoir d’incidence sur le contenu. Pourtant, il faut bien le souligner, les designers graphiques qui interviennent à ce moment sont parfois obligés d’ajouter une couche de structuration, le document n’étant pas assez riche sémantiquement pour pouvoir simplement se voir attribuer une feuille de style. La faible structuration d’un document ou le manque de communication entre celui qui écrit et celui qui met en forme en sont les principales raisons.
Pour définir un graphisme et l’appliquer à une publication, le designer dispose d’un logiciel de publication assistée par ordinateur – plus communément appelé logiciel de PAO. Dans ce secteur Adobe a une position de leader avec le logiciel InDesign. Cet outil « est conçu pour servir de façon satisfaisante le créatif » (Masure, 2011) : toutes les options d’édition sont optimisées, l’interface est pensée pour faciliter chaque action. Les possibilités créatives se font au dépend de la structuration, l’attribution d’une sémantique étant décorrélée de l’agencement graphique : ces deux phases sont hermétiques. Par ailleurs le logiciel qu’est InDesign pose deux problèmes :
- l’action de son utilisateur est limitée à une maîtrise de l’outil plutôt qu’à une maîtrise d’une activité : créer un rendu graphique et l’appliquer et non seulement activer des fonctions – aussi complexes soient-elles ;
- InDesign est à ce point répandu que la question de l’uniformisation des pratiques peut être posée : si un corps de métier utilise un même outil, cela ne crée-t-il pas des gestes ressemblants ?
Cette phase d’orchestration graphique se base donc sur des opérations d’inscription, de structuration et de révision. Jusqu’ici il est possible de travailler sur des versions successives d’un même fichier. Cette nouvelle étape vient interrompre cette continuité, en effet les logiciels de PAO, et plus particulièrement le logiciel InDesign, ont leur propre format. La chaîne d’édition classique connaît donc une rupture dans son fonctionnement :
- le format n’est plus le même – d’un .doc à un .indd par exemple –, et ce changement implique un problème d’accès aux contenus pour les intervenants d’un projet : un auteur qui ne dispose pas du logiciel de PAO utilisé dans la chaîne par un graphiste ne peut pas lire le fichier ;
- cette nouvelle étape est définitive (Fauchié, 2018), puisqu’il n’est pas possible pour d’autres personnes que le ou la graphiste d’opérer sur le fichier, comme précisé plus avant. Certes des corrections sur le texte sont toujours possibles, mais dépendent des personnes disposant et maîtrisant le logiciel de PAO ;
- l’interopérabilité est donc inexistante, puisqu’il n’est pas possible de travailler avec une même source (Blanc & Fauchié, 2017).
Il nous faut préciser un point important : la typographie, au sens de la composition d’un texte, est un travail qui requiert des compétences précises. L’application de règles élaborées et nombreuses – gestion des insécables et des césures, justification ou gestion des drapeaux, gestion des blancs, etc. – nécessite un outil lui aussi complexe, et puissant. L’hégémonie de certains logiciels dans le domaine de la mise en page n’est donc pas due uniquement à la volonté d’une entreprise – Adobe pour la citer – ou au manque de connaissance de ces praticiens, mais plutôt à la complexité inhérente de cette action. Des alternatives émergent, mais avant de les découvrir nous allons nous concentrer sur la production des formes d’un document ou d’un livre : leur diversité ne présente-t-elle pas un nouveau défi pour celles et ceux qui les orchestrent ?
3.1.4. Générer les formes et formats, publier
Écrire et manier un texte, mettre en forme un document, envisager un livre. Une chaîne de publication se constitue autour d’un objectif clair : mettre à disposition une pensée, une réflexion, une histoire. Avant de rendre public un livre, de le publier, il faut considérer les formes qu’il peut prendre. Celles-ci sont elles-mêmes liées aux enjeux de diffusion et de distribution : où sera accessible le livre ? À quelles conditions ? Pour quelles situations de lecture ? Le livre imprimé n’est plus le seul résultat permettant de consulter des contenus organisés, et le livre numérique ne peut pas être la seule émanation numérique. Mais alors, quelles contraintes imposent ces nouvelles expressions du livre à la fois pour celles et ceux qui les produisent, mais également pour celles et ceux qui les conçoivent ?
« L’édition peut être comprise comme un processus de médiation qui permet à un contenu d’exister et d’être accessible. » (Epron & Vitali-Rosati, 2018) La publication ou l’édition consiste donc à produire une forme tangible qui peut être consultée, cette production désignant – peut-être maladroitement – l’ensemble des étapes déjà décrites ici. Cet acte de mise à disposition ne peut pas être déconnecté des questions de diffusion, de distribution et de formes : si une publication académique est diffusée sur une plate-forme qui regroupe d’autres revues ou livres, le format produit ne peut pas être seulement un PDF destiné à l’impression. Une version sémantiquement riche au format XML est probablement nécessaire pour palier aux limites d’un format figé comme le PDF.
Le codex, la matérialisation du livre que nous connaissons et pratiquons depuis plus de deux mille ans, est à la fois une évolution technologique majeure de notre civilisation, et un objet en mouvement. Depuis l’invention de l’imprimerie avec la presse à caractères mobiles de Gutenberg (Jampolsky, 2017), jusqu’aux expérimentations récentes autour de l’enrichissement des supports physiques à l’aide du numérique, le livre est loin d’être immobile. Comme nous avons pu le voir dans la première partie, Alessandro Ludovico présente de nombreux exemples de projets éditoriaux alternatifs (Ludovico & Cramer, 2016), considérant l’édition dans son acception large – presse, magazine, livre, etc. Ce que nous pouvons retenir de ce panorama, c’est que le « processus de médiation » (Epron & Vitali-Rosati, 2018) qu’est l’édition prend désormais de nombreuses formes : impression au format poche peu coûteuse, diffusion sur Internet, version imprimée luxueuse, etc.
Avant d’aborder la question du livre numérique, intéressons-nous à un procédé qui semble bouleverser le monde du livre et plus particulièrement l’édition : l’impression à la demande – ou POD pour Print On Demand en anglais. Cette technique consiste en la fabrication rapide de livres à l’unité, et non plus dans une logique de « tirage » qui représente des coûts importants (André, 2009). Il s’agit à la fois d’une évolution technique d’impression, mais surtout d’une nouvelle organisation pour les éditeurs et les imprimeurs. L’impression à la demande restreint fortement les questions d’investissement et de temps : l’éditeur n’est plus dans l’obligation d’investir pour obtenir un minimum de 500 exemplaires en impression offset et de gérer ensuite un stock, et l’imprimeur est en mesure de fabriquer un livre en quelques minutes. Le lecteur, lui, peut obtenir un ouvrage – commande, fabrication et livraison comprises – en quelques jours. Basée sur la technique d’impression numérique, la POD nécessite une infrastructure technique et logistique capable de gérer un catalogue, de fabriquer ces livres, et de les expédier. L’impression à la demande nécessite des réglages spécifiques pour la génération d’un format PDF, et est peut-être, dans la gestion du processus, le résultat le plus visible du numérique dans la chaîne d’édition. La POD est l’objet d’autres questionnements, notamment les questions de droits d’auteur, de diffusion, et d’effort de médiation de la part de l’éditeur (Bon, 2016).
Le livre numérique a été, depuis 2006, le principal candidat comme remplaçant du livre imprimé, et un espoir d’essor économique pour les éditeurs (Benhamou, 2014). Et par « livre numérique » il faut comprendre « livre numérique homothétique », c’est-à-dire un fichier EPUB qui a les mêmes propriétés qu’un livre imprimé : l’organisation en chapitres, un sommaire ou une table des matières, et peu d’enrichissements en dehors des propriétés du dispositif de lecture numérique. Le format standardisé et ouvert EPUB a été, dans ce contexte, le moyen de vendre des fichiers numériques : l’organisation et la mise en portabilité de fichiers numériques lisibles par de nombreuses applications, souvent avec l’ajout de mesures techniques de protection. Encore aujourd’hui lorsque les termes livre et numérique sont associés, le livre numérique semble être la seule expression possible. Le « livre web » (Fauchié, 2017) est pourtant un objet d’édition séduisant : un site web organisé en chapitres, des outils de navigation rappelant ceux des dispositifs de lecture numérique, et même la capacité technique de rendre ces contenus consultables hors connexion. Ne plus devoir télécharger un fichier, disposer de capacités graphiques plus avancées, et ne pas dépendre d’applications spécifiques : un livre web peut être accessible directement depuis le Web, le design des sites est plus avantageux que celui du format EPUB, et seul un navigateur est utile pour lire. Cette nouvelle forme d’édition pose toutefois une question économique : comment rentabiliser un projet éditorial et commercial si l’un des principaux accès est gratuit ? Les exemples donnés par Alessandro Ludovico dans Post-Digital Print démontrent qu’une pluralité d’objets physiques et numériques, dont certains payants voire en tirage limité, peut constituer un projet économiquement viable (Ludovico & Cramer, 2016). D’un autre côté, le livre web pourrait être l’une des médiations possibles pour favoriser l’émergence de nouvelles pratiques de diffusion du savoir, et notamment de savoir académique :
Si « penser ce n’est pas produire des pensées mais les saisir » (Gottlob Frege), alors il est crucial de penser les conditions de ces opérations de saisie. Dès lors que la pensée n’existe pas en dehors de sa matérialité, le rôle du design dans la transmission des savoirs va bien au-delà de leur embellissement.
(Masure, 2018).
Impression classique, EPUB, web, impression à la demande : autant de formes différentes, dont certaines n’ont pas encore été inventées, qui impliquent des contraintes particulières dans l’opération de publication ou d’édition. Comment afficher les images en couleurs sur une liseuse à encre électronique à écran noir et blanc ? Comment fabriquer, en impression à la demande, un livre épais qui nécessiterait une reliure autre qu’un dos collé habituellement utilisé en POD ? Comment anticiper l’affichage d’un livre web dont l’utilisateur a désactivé la feuille de style ? Ces paramètres peuvent avoir des incidences à la fois sur la conception des contenus – peut-être minimes –, mais surtout sur la façon dont la forme du livre est conçue. Si la typographie est « la seule chose qui reste du papier dans le livre numérique » (Perret, 2018), ne faut-il pas revoir en profondeur l’attention apportée au design des publications ? Si le livre numérique a plus à voir avec le flux (Tangaro, 2017), comment appréhender l’acte de publication et le rôle de l’éditeur ?
3.1.5. Vers un système ?
À travers cette définition critique des différentes étapes d’une chaîne de publication nous pouvons faire plusieurs constats, tant en termes d’approche théorique que pratique. Il faut tout d’abord noter que la culture technique des workflows dédiés à l’édition est riche, des moyens importants sont déployés pour la conception et la production des livres. Nous avons fait l’économie d’une analyse de l’évolution des programmes et des logiciels depuis l’avènement de l’informatique (Masure, 2014), mais nous constatons un déploiement de prouesses pour prolonger la tradition typographique, pour fabriquer des livres de qualité et pour faciliter le travail des auteurs, des éditeurs ou des designers. Toutefois lors de cette exploration nous nous sommes confrontés à plusieurs obstacles : le manque de compréhension lié à la structuration des contenus, la confusion entre le fond et la forme, le manque de réversibilité lors de la composition graphique, la difficulté de générer conjointement les manifestations imprimée et numérique d’un livre, ou la dépendance à des outils hégémoniques. Les contraintes sont nombreuses et des tentatives de remplacement apparaissent, mais nous souhaitons formuler ici une hypothèse. L’enjeu n’est pas uniquement de supplanter des outils fermés par des logiciels ouverts, ou de mettre en place des procédés complexes de conversion de formats d’un programme à un autre. Il est nécessaire de modifier l’approche globale, comme en témoignent les cas présentés dans la partie 2. À ce sujet le traitement de texte est emblématique : la question n’est pas tant les fonctionnalités et l’ouverture du logiciel – l’objectif d’interopérabilité est pourtant louable –, la confusion entre structure et mise en forme est finalement la même avec Microsoft Word et LibreOffice Writer.
La notion même de chaîne suscite une interrogation : les étapes de publication se doivent-elles de former un ensemble monolithique ? Nous pouvons convenir qu’il y a un intérêt à utiliser la même source pendant tout le processus de publication, notamment pour permettre à tous les acteurs d’intervenir au même titre, en revanche la désolidarisation des étapes est nécessaire. Qui plus est, la publication doit être un système cohérent composé de modules en synergie – pour reprendre une expression de Gilbert Simondon –, plutôt qu’une série de paliers irréversibles et enchaînés qu’il faudrait suivre de façon linéaire. La chaîne de publication peut être considérée comme un ensemble de fonctions imbriquées qui se répondent entre elles, c’est la définition de l’« objet technique concret » (Simondon, 2012). La structuration d’un document permet de lui attribuer une mise en forme, ces deux étapes sont liées, elles s’articulent : cette description des étapes et l’apport des théories de Gilbert Simondon nous permet de modéliser un nouveau schéma que nous nous proposons d’exposer par la suite. L’adaptabilité des fonctions d’un processus de publication permet d’entrevoir non plus une chaîne, mais un système : un ensemble d’éléments interagissant entre eux selon des objectifs et des règles. De nombreuses alternatives émergent pour repenser la façon de produire des livres, comme le collectif PrePostPrint déjà évoqué (Fauchié, 2017). L’influence du numérique sur le livre et ses moyens de production s’est traduite par la numérisation des outils, puis par l’émergence de nouvelles formes – en l’occurrence le livre numérique. Il s’agit désormais d’entrevoir la transformation des méthodes et des techniques.
-
Plusieurs services de pad sont disponibles comme Framapad (https://framapad.org/) proposé par l’association Framasoft. ↩