Nous proposons d’abandonner le terme de « chaîne » au profit de celui de « système » : les étapes d’un processus de publication ne doivent plus être considérées comme une suite linéaire, mais comme un assemblage sophistiqué, une synergie de composants interagissant de façon dynamique, et non plus linéaire – une étape après l’autre. Cette proposition se base sur les constats mis en avant dans la partie précédente, notamment la confusion entre structure et mise en forme, le manque de compatibilité, la discontinuité des étapes ou la dépendance à certains logiciels. Si les dix dernières années ont été consacrées à trouver des alternatives libres et ouvertes à des logiciels fermés et privateurs1, ce mouvement en faveur d’un remplacement peut, dans le domaine de l’édition – écriture, structuration, collaboration, composition – être dépassé. Les projets portés par Getty Publications ou O’Reilly exposés dans la seconde partie illustrent ce mouvement : les traitement de texte et logiciel de publication assistée par ordinateur sont écartés au profit d’une nouvelle conception du processus de publication. La notion même de « système » introduit le fait que les outils ne doivent pas remplir des fonctions les unes après les autres, selon un procédé linéaire, mais être assemblés d’une manière cohérente, afin de dialoguer entre eux.
L’association efficiente des outils qui constituent un workflow d’édition requiert une circulation d’information entre eux. Les questions de compatibilité adviennent assez vite lorsqu’il s’agit de communiquer entre les métiers qui composent la chaîne d’édition : de deux systèmes d’exploitation distincts et deux logiciels de traitement de texte dissemblables découlent au mois quatre sources de problèmes (Reichenstein, 2016). Les enjeux d’interopérabilité sont peut-être encore mal appréhendés dans le domaine de l’édition, nous tentons ici de trouver des solutions pertinentes.
Une dimension supplémentaire découle de l’interopérabilité des outils, celle de pouvoir les échanger à la manière de briques logicielles. Cette dimension de modularité signifie que le système de publication est d’abord composé de fonctions, ces dernières sont remplies par des outils. Le processus global n’est pas orienté par les outils, mais par les fonctions.
Nous l’avons déjà vu, les formes du livre sont aujourd’hui principalement l’imprimé, le livre numérique homothétique et, en marge, le livre web. Embrasser ces différentes possibilités, et être en capacité de générer facilement autant un PDF d’impression qu’une version web a des conséquences sur le système de publication. Celui-ci ne doit plus être orienté pour l’imprimé et produire d’autres formats plus exotiques dans un deuxième temps, il doit être multiforme par défaut.
L’interopérabilité, la modularité et la multiformité : trois principes qui soutiennent un système de publication pour éditer des livres avec le numérique. Ces trois principes sont interdépendants, et ne sont pas exsangues de problèmes ou de critiques. Si ce nouveau modèle était en capacité de résoudre toutes les difficultés présentées dans la partie précédente, il aurait déjà été adopté. Nous devons donc être exigeant quant à la présentation de ces trois fondements, et extraire les nouvelles contraintes imposées par ce modèle.
3.2.1. Interopérabilité
L’interopérabilité est un enjeu critique dans une chaîne de publication, puisqu’il s’agit de la communication entre les différents outils qui la composent. Elle permet une continuité d’une étape à une autre, par exemple entre l’étape d’écriture et de validation d’un texte, et celle de mise en page. Si un traitement de texte utilise un format non ouvert, il sera probablement très complexe pour un logiciel de composition de l’interpréter, il y a donc une absence d’interopérabilité. Quelles sont les possibilités pour réaliser une telle fluidité de circulation d’informations entre les outils qui constituent un système de publication ? Quels sont les contraintes et les effets d’une réelle interopérabilité ?
La continuité, dans une chaîne de publication, est donc la capacité à passer d’une étape à une autre et donc d’un outil à un autre, facilement. Pourquoi est-ce que cette continuité, sans friction, est nécessaire ? Pour deux raisons que nous souhaitons exposer avec le plus de clarté possible, et qui illustrent par ailleurs ce concept de « continuité ».
L’étape de composition crée une tension dans le processus d’édition, en effet le logiciel utilisé pour la mise en forme ne peut pas être accessible à tous les intervenants du projet. Par exemple lorsqu’un texte a été rédigé, relu et corrigé avec un traitement de texte par des auteur et correcteur, la composition est réalisée avec une autre application : un logiciel de publication assistée par ordinateur. Ce dernier peut importer le fichier généré par le traitement de texte, et le designer graphique se charge alors de la mise en page du texte dans ce nouvel environnement informatique. Si l’auteur souhaite intervenir à nouveau sur le texte pour intégrer des modifications, il rencontre une difficulté puisqu’il ne peut pas faire le chemin inverse, c’est-à-dire importer dans un traitement de texte le fichier produit par le logiciel de composition. Deux solutions sont alors possibles : l’auteur dispose du même logiciel de mise en forme que le ou la graphiste – et le maîtrise –, ou il doit laisser une personne compétente réaliser cette action. Le texte doit être fixé avant qu’une mise en forme puisse lui être attribuée, il y a donc, à ce moment du processus, une rupture.
Deuxièmement, les formats des fichiers des traitements de texte et des logiciels de PAO, même s’ils sont désormais basés sur des standards XML, restent illisibles pour le commun des mortels. La question de l’interopérabilité ne concerne pas que les programmes ou les machines, mais aussi les humains qui les manipulent. L’utilisateur, pour lire un fichier issus de ces outils, doit forcément passer par ceux-là. Ces fichiers sont comme des boîtes noires, difficile de savoir ce qu’ils contiennent hormis les informations que le logiciel compatible nous transmet. Cela a une incidence sur la circulation et la gestion des fichiers. Observons le fonctionnement adopté dans un autre domaine, le développement informatique. Celui-ci n’est pas pris au hasard car il est également centré sur du texte, sauf qu’il s’agit cette fois de code. Les projets sont un ensemble de fichiers organisés, chacun d’entre eux porte des informations lisibles avec un éditeur de texte, aucun logiciel particulier n’est nécessaire pour lire le contenu – la question de l’interprétation est décorrélée.
Pour contourner cette problématique de discontinuité liée aux formats et aux logiciels, plusieurs procédés existent, l’un d’eux est LaTeX. LaTeX est l’association d’un langage de balisage, TeX, et d’un processeur qui génère différents formats à partir de cette source (Rouquette, Chabannes, & Rouquette, 2012). Créé par Leslie Lamport en 1983 à partir de TeX de Donald Knuth — lui-même créé en 1977 —, LaTeX est pensé pour l’impression de documents — article, thèse, livre – et donc la production de fichiers PDF. LaTeX est un système bien antérieur aux traitements de texte, et il repose sur les éléments suivants :
- un langage de balisage pour inscrire et structurer du texte : niveaux de titre, liste, notes de bas de page, pagination, italique, tableau, légendes, mais aussi des formules mathématiques ;
- l’édition des fichiers .tex se fait dans un éditeur de texte. La syntaxe est compréhensible et plus légère que du HTML, en revanche la lecture d’une source en .tex n’est pas chose aisée en raison des nombreuses balises ;
- la génération du format PDF se fait classiquement depuis un terminal, mais des logiciels avec des interfaces graphiques rendent cette génération plus simple ;
- dans la mesure où les fichiers .tex et associés — notamment pour gérer les bibliographies ou les feuilles de style — sont des fichiers texte, ils peuvent être ouverts et lus sur n’importe quel dispositif disposant d’un éditeur de texte sans risque de compromettre le fichier.
LaTeX nécessite de disposer d’une infrastructure particulière pour générer les formats de sortie : elle peut comprendre des extensions destinées à la gestion des bibliographies ou des mises en forme spéciales, en plus d’une collection de programmes pour le fonctionnement général. Cet ensemble est désigné sous le nom de « distribution LaTeX », tant il s’agit d’un mini-système d’exploitation typographique. LaTeX a été conçu pour composer très habilement la typographie d’un document, jusqu’au dessin de caractères avec Metafont (Vallance, 2015). Si LaTeX est stable et puissant, offrant la possibilité d’une structuration et d’une mise en forme très maîtrisées, idéale pour l’édition scientifique (Guichard, 2008), son utilisation demande un apprentissage important, certaines fonctionnalités sont complexes à manipuler – même avec des logiciels qui en facilitent la compréhension. Par ailleurs, si le rendu pour l’impression est irréprochable il est néanmoins limité, les modèles et feuilles de style nécessitent des compétences importantes. Quelques maisons d’édition ou graphistes ont utilisé LaTeX pour structurer et composer des livres, et non pas uniquement pour des articles comme c’est le cas le plus répandu, mais ces expériences sont très rares, principalement parce que le degré de connaissances requises est élevé, et les détournements du processus nécessaires. Enfin, ce n’est pas un procédé pensé pour la génération de formes numériques – même si cela est possible, notamment du format HTML. LaTeX est une approche programmatique pour concevoir et produire une publication figée, et ce système remplit parfaitement cette fonction.
Entre d’un côté la complexité des formats des traitements de texte et de l’autre la difficulté d’usage de LaTeX et son manque de multiformité, nous pouvons trouver une alternative qui répond à plusieurs préalables. Nous avons besoin d’un moyen d’inscrire et de structurer du texte pour pouvoir en générer des formes diverses, tout en ayant la possibilité de voir et de comprendre la structure du document. Le mode WYSIWYM, abordé dans la partie 3.1.1., répond à ces exigences : la qualification des contenus est prioritaire sur l’aperçu graphique qui en est donné. Les langages de balisage léger sont l’application du mode WYSIWYM, le plus célèbre et répandu d’entre eux est Markdown. « Un langage de balisage n’est rien d’autre qu’un système d’annotation d’un document qui s’effectue d’une telle manière qu’il est possible de distinguer ces balises, ces annotations, du texte que l’on annote. » (Dehut, 2018) Markdown a été inventé pour pouvoir écrire facilement en HTML, sans écrire en HTML : quelques balises permettent de structurer du texte, et sont compréhensibles par des humains et interprétables par différents outils ou processeurs.
Le rayonnement de Markdown est tel que ce langage peut être considéré comme la norme de l’écriture numérique (Fauchié, s. d.), bien au-delà de l’écosystème technique auquel il est habituellement réservé. Étant à la fois aisément convertissable en HTML et lisible par des non-techniciens, ce format peut devenir la source utilisée tout au long d’un processus d’édition. Quire, le système de publication numérique de Getty Publications présenté dans la seconde partie, emploie Markdown. Stylo, l’éditeur de texte pour les sciences humaines et sociales – conçu par la Chaire de Recherche du Canada sur les écritures numériques en partenariat avec Érudit (Vitali-Rosati, 2018) –, utilise Markdown.
Markdown est une initiative du domaine du développement web, il a été conçu par des développeurs, il a de commun avec des formats de fichier de programmation d’être tout simplement du texte brut – comme un fichier PHP, un fichier JavaScript ou un fichier XML. Il est possible de mettre à plat un projet grâce à des fichiers en texte brut, c’est-à-dire de déconstruire le projet en unités indépendantes et intelligibles quels que soient la situation et l’environnement – même si les langages de programmation nécessitent des connaissances précises pour pouvoir être interprétés. Cette mise à plat permet d’envisager un mode de gestion particulier des fichiers : ils ne sont plus manipulés de la même façon. Avec un système de contrôle de versions, les actions d’enregistrement, de révision et de validation changent totalement. Git est actuellement le plus populaire de ces systèmes, offrant des fonctions puissantes de versionnement.
« Les systèmes de gestion de versions comme Git fonctionnent en conservant un exemplaire de chaque version successive d’un projet dans ce que l’on appelle un repository (ou dépôt), dans lequel vous validez, ou committez, des versions de votre travail qui représentent des pauses logiques, comme des points de sauvegardes dans un jeu vidéo. »
(Demaree & Brown, 2017)
À l’écrasement successif des fichiers succède une ligne du temps faite de versions et de branches dans laquelle il est possible de naviguer. Voyager dans le temps d’un projet, une opération vitale dans un environnement qui repose sur des enregistrements informatiques, est désormais vraisemblable. Il est intéressant de constater que Git est déjà utilisé pour autre chose que du code, nous l’avons vu avec la revue Distill dans la seconde partie : les révisions sont versionnées, le code source des articles rendu public, chaque action est décrite, etc. Cette pratique est également en cours pour la gestion de textes techniques, notamment pour améliorer la collaboration autour de documents de travail au sein de structures diverses, c’est le cas pour les équipes marketing ou juridiques de l’entreprise GitLab (GitHub, 2018) – qui, forcément, utilisent le produit qu’elle promeut : Git.
Ainsi Markdown, ou d’autres syntaxes légères comme AsciiDoc, permet d’obtenir aisément des documents structurés auxquels une feuille de style peut être attribuée, ce qui convient tout à fait pour une publication numérique. La question principale reste donc la génération d’un format PDF pour l’impression, et c’est justement le format HTML, ou une version XML, qui peut être la base de cette version imprimable. Une solution logicielle propriétaire assure cette conversion du format HTML vers un PDF de grande qualité, et c’est d’ailleurs le choix des systèmes Quire ou Electric Books.
To convert our content to print-ready PDF, we use PrinceXML Prince is the only proprietary tool in our workflow, because there are no open-source alternatives with matching functionality at the moment.
(Attwell, 2017).
PrinceXML est un programme fermé et propriétaire, et relativement coûteux, des initiatives diverses se sont rassemblées pour proposer des alternatives plus ouvertes, constituant un champ de recherche très actif. À la suite d’HTML2print (OSP, 2017) ou de Vivliostyle (Taquet, 2017), Paged Media se consacre depuis 2017 à cette quête de l’impression d’une source HTML, publiant ses premiers résultats et organisant des temps d’échange autour de ces questions techniques et graphiques (Blanc, 2018). Le collectif PrePostPrint est également né de cette volonté de s’extraire des logiques logicielles classiques et fermées (Fauchié, 2017). Il serait en effet dommage de passer d’une hégémonie – le logiciel de publication assistée par ordinateur Adobe InDesign – à une autre – PrinceXML.
La question de la continuité est soutenue par l’enjeu de l’interopérabilité, le moyen de rendre les étapes d’un processus de publication réversibles est l’usage d’un standard commun pour la description et la structuration des contenus. Un langage de balisage léger à la syntaxe riche mais compréhensible comme le format de texte brut Markdown peut venir pallier aux difficultés de communication d’une application à une autre. Utiliser un format brut offre par ailleurs la possibilité de versionner les contenus, et non plus de fonctionner par écrasements successifs. Si des solutions ont été mises en place depuis déjà très longtemps – à l’échelle de l’histoire informatique –, il est aujourd’hui nécessaire de simplifier ces processus et surtout de prévoir la dimension multiforme d’un même projet d’édition. L’interopérabilité ouvre une perspective déterminante, celle de pouvoir construire un système de publication modulaire : le système est architecturé selon des objectifs définis clairement, un module remplit une ou plusieurs fonctions. C’est ce que nous allons examiner dans le point suivant.
3.2.2. Modularité
L’interopérabilité ouvre la possibilité de ne pas dépendre d’un ou plusieurs logiciels précis, et donc d’envisager un système modulaire. D’une chaîne aux étapes liées entre elles par la contrainte des outils, nous passons à un système ouvert dont les phases peuvent être réversibles. Les étapes de publication sont traduites en fonction d’un système, de l’écriture à la publication en passant par la correction et la mise en page, et ces fonctions peuvent être isolées puis rattachées entre elles. Cette question de la modularité est directement issue de la conception technique de Gilbert Simondon : la synergie d’un « objet technique » dépend des relations entre les fonctions de cet objet, elles ne doivent pas agir sans connexion entre elles. Étudions tout d’abord des systèmes modernes de publication qui n’intègrent pas totalement cette dimension, puis détaillons comment un processus de publication peut devenir modulaire.
Depuis plusieurs années l’infrastructure de recherche Numédif (http://www.numedif.fr), portée par la Maison de la recherche en sciences humaines de Caen et la Fondation Maison des sciences de l’homme de Paris, développe le projet Métopes, « Méthodes et outils pour l’édition structurée ». Métopes, atypique dans le paysage de l’édition, dans la façon de produire des livres, est conçu pour éditer et diffuser des textes complexes structurés, en versions imprimée et numérique, sur le modèle du Single Source Publishing – d’une même source XML sont produits différentes formes de publication (« Single-source publishing », 2018). Utilisée par des Presses universitaires en France et dans le monde, cette chaîne éditoriale vise à remplacer le duo traitement de texte et logiciel de publication assistée par ordinateur, bien trop limité pour l’édition scientifique. La base de Métopes est le format XML-TEI, un format XML qui permet de décrire avec la précision scientifique nécessaire des données textuelles. À partir d’un texte structuré exporté depuis un traitement de texte, et d’un schéma de données (TEI), une publication est éditée, structurée et enrichie pour ensuite être diffusée sous différentes formes : PDF pour la consultation et l’impression, livre numérique au format EPUB, et formats propres aux plates-formes de diffusion comme du XML pour Cairn.info ou Open Edition.
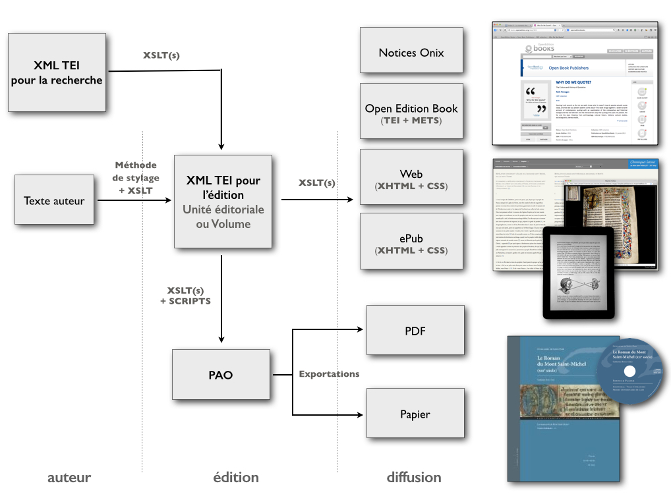
La force de Métopes est de pouvoir répondre aux nécessités du domaine académique : des contenus structurés – identification très fine de contenus et métadonnées riches –, une dimension de flux pour une connexion aux principales plates-formes de diffusion en sciences humaines et sociales, et la génération de formats divers – XML, PDF, EPUB, web. Métopes est un système complexe en partie modulaire, il nécessite des formations adaptées pour son application ainsi que des méthodes d’export et d’import spécifiques pour passer d’une étape à une autre – par exemple une fois un texte édité, il doit être exporté vers un logiciel de PAO, en l’occurrence InDesign. Métopes a quelques limites, « l’objectif est de ne pas bouleverser le travail de rédaction : l’auteur ne doit pas être perturbé dans son travail » (Muller, 2016), Métopes génère ainsi une étape irréversible, celle de l’écriture. Une fois le texte intégré dans la chaîne éditoriale, l’auteur ne peut plus intervenir dessus. Hors du contexte de la publication universitaire, Métopes devient trop compliqué à mettre en place. Par ailleurs Métopes n’a pas pour objectif de répondre à la question de la dépendance à un logiciel particulier de PAO ou à un traitement de texte.
Hors du champ de l’édition universitaire, d’autres systèmes modulaires ont été mis en place en appliquant le principe du Single Source Publishing, cette fois avec une syntaxe bien plus légère et accessible que XML et le schéma de données TEI. Des publications non académiques, mais aux exigences similaires, sont construites avec les éléments suivants :
- une syntaxe de description du contenu, pour rédiger et structurer du texte pouvant être agrémenté d’images ;
- un langage de description des données, pour décrire des objets divers, comme des éléments d’une bibliographie ;
- un langage de mise en forme, pour décrire la présentation de contenus ;
- un système de gestion de versions, pour enregistrer, gérer et valider les fichiers ;
- un processeur en charge de la conversion des contenus structurés, pour obtenir un format interprétable par un dispositif de lecture – un navigateur web par exemple –, ou convertissable par un générateur PDF ;
- un générateur, pour convertir un format HTML en PDF destiné à l’impression.

Ce modèle est celui adopté par Getty Publications ou Electric Book Works, les différences entre ces deux exemples sont techniques et sectoriels, Getty Publications éditant des catalogues, et Electric Book Works proposant leur solution à des structures éditant des ouvrages de non-fiction ou des manuels. Ici chaque élément – la description du contenu, la description des données, la mise en forme, le versionnement, la conversion, la génération – correspond à une ou plusieurs étapes du processus de publication, et des outils sont mis en œuvre pour les appliquer. Nous pouvons ainsi compléter la liste ci-dessus avec le système de publication de Getty Publications, décrit plus longuement dans la seconde partie de ce mémoire :
- une syntaxe de description du contenu : le langage de balisage léger Markdown ;
- un langage de description des données : le langage de représentation de données YAML ;
- un langage de mise en forme : des feuilles de style au format CSS ;
- un processeur : un générateur de site statique (Taillandier, 2016) qui transforme et organise des contenus écrits en Markdown en HTML ;
- un générateur : PrinceXML qui convertit des fichiers HTML, associés à des feuilles de style, en format PDF destiné à l’impression.
Ce modèle est dit modulaire car chacun de ces éléments est une brique interchangeable. Prenons plusieurs exemples dans le système de publication de Getty Publications décrit ci-dessus : la syntaxe de description du contenu est Markdown, mais cela peut être un autre langage de balisage léger comme AsciiDoc. Ensuite le processeur est un générateur de site statique, en l’occurrence Hugo (Biilmann, 2015), qui assure la conversion de fichiers Markdown – mais cela pourrait être AsciiDoc – en fichiers HTML selon des gabarits pré-définis, mais cela aurait pu être le convertisseur Pandoc – par ailleurs utilisé dans d’autres systèmes de publication. Enfin, en ce qui concerne le générateur de format d’impression, Vivliostyle peut remplacer PrinceXML – il faut tout de même noter ici une différence de qualité. En plus d’être remplaçables, ces briques interagissent entre elles, créant une synergie que décrit Gilbert Simondon :
[…] l’objet technique progresse par redistribution intérieure des fonctions en unités compatibles, remplaçant le hasard ou l’antagonisme de la répartition primitive ; la spécialisation ne se fait pas fonction par fonction, mais synergie par synergie.
(Simondon, 2012, p. 41)
Comme nous l’avons brièvement exposé dans la première partie lors de l’étude du texte Du mode d’existence des objets techniques, un système de publication est une forme de progrès technique par rapport aux chaînes de publication classiques. D’une part les différentes briques ou modules qui composent le processus éditorial de Getty Publications sont ouverts, modifiables, partageables. L’évolution de ces outils ne dépend pas d’un éditeur de logiciel, mais d’un ou plusieurs développeurs, voir d’une communauté dans le cas de projets étendus. D’autre part si un module devient obsolète alors il est possible de le remplacer par une autre brique qui réalisera au moins les mêmes fonctions, sinon plus. Les fonctions sont certes modulables et d’une certaine façon interchangeables, mais elles sont en relation, la modification d’un élément aura probablement une incidence sur l’ensemble du système.
Deux points sont à souligner avant d’aborder la question des différentes formes d’une publication et des enjeux liés. En premier lieu l’apport pour Getty est riche sur plusieurs niveaux (Gardner, 2017), autant concernant la facilité de produire des formes diverses, que l’évolutivité de la chaîne. Getty Publications n’a pas besoin de produire du XML, et par exemple du XML TEI, mais cela pourrait être une possibilité. Ensuite la modularité a une limite qu’il nous faut prendre en compte : quand bien même ces briques sont à la fois indépendantes – elles peuvent être remplacées – et liées – elles ne sont pas isolées –, elles créent une nouvelle forme de contrainte. Si les principales dépendances d’une chaîne d’édition classique sont les logiciels – et principalement le traitement de texte et le logiciel de PAO –, celles d’un système modulaire de publication sont des programmes et leurs propres dépendances. Dans le cas de Electric Book Works qui a développé un workflow similaire à celui de Getty Publications (Attwell, 2017), le processeur est le générateur de site statique Jekyll. Ce dernier est développé en Ruby, un langage de programmation reconnu mais qui nécessite d’être installé dans le système d’exploitation de l’utilisateur. Nous obtenons déjà 3 niveaux de dépendances : un processeur dépend d’un générateur de site statique, un générateur de site statique dépend d’un langage de programmation, un langage de programmation dépend d’un environnement informatique. À l’inverse, Getty Publications a remplacé le générateur de site statique Middleman (Gardner, 2015) par Hugo, sans que cela n’ait un impact important sur les phases d’écriture et de révision, ou de mise en forme. Ce sur quoi nous souhaitons insister est que la question n’est pas seulement celle de la dépendance à des logiciels, puisqu’ici elle semble se déplacer plutôt que de disparaître, mais la possibilité de faire évoluer cette chaîne, dans le temps.
[…] je voulais m’assurer que notre travail demeure accessible aussi longtemps que possible. »
(Gardner, 2017)
Peut-être que cette évolution et cette résilience ont un prix, celui de nouvelles dépendances.
3.2.3. Multiforme
Le nouveau modèle que nous proposons se base sur trois dimensions, elles-mêmes étant liées les unes aux autres. L’interopérabilité permet la modularité, et la modularité permet la multiformité. Au-delà de la capacité, il nous faut rappeler les contraintes d’un contexte en mouvement. Les formes du livre, ou d’une publication, ont beaucoup évolué, et sont souvent des déclinaisons du codex – cet objet hautement technologique. Que ce soit le livre de poche dans les années 1950, ou le livre numérique dans les années 2010, nous avons plusieurs exemples dans l’histoire contemporaine de l’édition que cette variété d’objets nécessite une adaptation. Le numérique est donc une opportunité pour déployer une diversité de formes, actuelles et futures. Nous devons présenter quelques-unes de ces évolutions du livre, tout comme nous devons analyser les solutions pour qu’un système de publication s’y adapte.
Le livre de poche a été une transformation majeure pour l’industrie du livre dans les années 1950 (Marti, 2008), suscitant l’enthousiasme ou le rejet (Sinard, 2017). Nous ne revenons pas ici sur les nombreux effets positifs de cette invention, qui concernent surtout l’accès à l’écrit et à la culture, mais également la façon dont le livre est conçu. Le livre de poche est une évolution du livre, ou plutôt une nouvelle déclinaison d’une publication. Cet objet bon marché est parfois utilisé pour comprendre, aujourd’hui, l’impact du livre numérique. Ce dernier est plus récent, même si le premier livre numérique a été créé en 1971 (Lebert, 2016), il ne se concrétise qu’autour des années 2006 et 2007 pour des raisons techniques et économiques. La standardisation d’un format, la mise à disposition de titres en numérique et enfin la commercialisation d’un dispositif de lecture numérique permettent une adoption significative de ce nouveau mode de lecture.
Si le livre numérique n’a pas eu le succès escompté, voir même que la « mort du papier » n’est en fait qu’une modification du « rôle » du document (Ludovico & Cramer, 2016, p. 32), l’ebook implique un bouleversement significatif pour les maisons d’édition. D’une approche figée – que ce soit le livre imprimé mis en forme à la page ou le format PDF qui n’est qu’un ersatz numérique homothétique – le livre devient liquide. Le format EPUB introduit en effet une reconfiguration continue du texte : en fonction de la largeur d’un écran une phrase peut occuper une ou plusieurs lignes ; selon les réglages typographiques d’un dispositif de lecture numérique ou des réglages de l’utilisateur, une page peut prendre un aspect totalement différent – voir figure ci-dessous.
[…] dans le passage du livre papier au livre numérique, le livre abandonne la forme de codex pour acquérir celle de « flux » numérique.
(Tangaro, 2017)

Parmi les nouvelles formes du livre, nous devons évoquer celle du « livre web », phénomène récent qui concerne principalement des ouvrages de non fiction – essais ou manuels techniques. Des initiatives apparaissent dès les débuts du Web pour diffuser facilement des textes de formats longs, mais c’est à partir des années 2010 que des web books sont réalisés pour répondre à plusieurs critères (Fauchié, 2017) : ensemble de pages structurées et organisées entre elles, contenus qui s’adaptent à la dimension de l’écran, liens hypertextes permettant de naviguer dans et hors du livre, facilités de diffusion d’un livre numérique via le Web, démarche d’ouverture avec des accès libres. Si plusieurs livres web ont été référencés sur un dépôt GitHub (https://github.com/antoinentl/web-books-initiatives) permettant de prendre la mesure de la diversité de ces projets, nous pouvons citer un « livre web » produit en 2016 : Resilient web design de Jeremy Keith (https://resilientwebdesign.com/) est un exemple emblématique de « livre web » en termes de design, de diffusion de contenus et d’édition. Jeremy Keith a mis en ligne ce court essai en auto-édition en décembre 2016 (Keith, 2016) à la suite de plusieurs ouvrages publiés notamment chez l’éditeur A Book Apart. Il s’agit d’un site web relativement classique composé d’une dizaine de pages. Des versions audio, PDF et EPUB sont également disponibles. Le site web comporte une particularité très intéressante : une fois qu’une page a été visitée, le site est consultable hors ligne (Keith, 2017), cet objet numérique devient une véritable alternative à des formats comme l’EPUB en termes de portabilité et d’accessibilité. Autre particularité : les sources du site web sont mises à disposition sur la plate-forme GitHub (https://github.com/adactio/resilientwebdesign/), toute personne maîtrisant Git ou l’interface de GitHub peut proposer des modifications aux contenus, qui pourront ensuite être validées par l’auteur. Le livre web peut « nous inciter à repenser la façon dont les savoirs sont élaborés et transmis » (Masure, 2018).

Alessandro Ludovico décrit avec beaucoup de précisions le mouvement formel que connaît l’édition depuis la fin du 19e siècle, la première partie de ce mémoire est justement consacrée à l’analyse de son ouvrage Post-Digital Print. Le concept d’« impression postnumérique » recouvre les formes diverses que prend le livre, voir une même publication. Il s’agit tout autant des versions – édition limitée de luxe, livre de poche, ebook –, ou ses axes de diffusion – la souscription avant disponibilité, des podcasts après, etc. Cette « hybridation » n’est possible qu’en étant en capacité de générer à la fois un PDF destiné à une impression en offset, un PDF pour une impression à la demande et des versions numériques – EPUB ou web.
Revenons au cas qui nous occupe depuis le début de ce mémoire : le système de publication de Getty Publications – analysé dans la partie 2. Getty Publications a donc mis en place un moyen de produire des expressions d’une publication aussi variées qu’un site web, un livre numérique, un PDF et un ouvrage imprimé. En soi il ne s’agit pas d’un exploit, nombre de maisons d’édition ont su adapter leur chaîne d’édition pour produire ce type d’artefacts. La particularité réside dans le fait de faire reposer ce système sur une même source : un ensemble de modules regroupé sous le nom de Quire œuvre à générer des formats très divers. Produire un livre numérique au format EPUB n’est plus une tâche supplémentaire comme cela peut être le cas pour de nombreux éditeurs (Faucilhon, 2016). Tout comme Atlas, le système de publication d’O’Reilly Media également abordé dans la partie 2, Quire est une approche nouvelle dans le domaine de l’édition. Ces deux exemples ont des limites : Quire est web first, c’est-à-dire que les mécanismes en place sont avant tout dirigés pour produire un site web ; Atlas est le résultat de développements spécifiques et non un assemblage de technologies disponibles.
Getty Publications et O’Reilly Media sont deux structures d’édition particulières, « de niche » pourrait-on dire, tant les domaines abordés sont spécifiques : catalogue de musée et manuels techniques. Du côté d’un grand groupe d’édition de livres plus « grands publics », des avancées techniques de ce type sont également mises en place : depuis plusieurs années Hachette produit des livres imprimés et des ebooks avec les technologies du Web (Cramer, 2017). Après un import de fichiers issus de traitements de texte, des formats HTML et CSS sont la base de la production de fichiers EPUB – pour le livre numérique – et PDF – pour le livre imprimé. Ainsi plusieurs milliers de titres dans le domaine du trade – l’édition grand public qui concerne les romans, les essais ou la littérature jeunesse – sont produits depuis 2007, sans avoir recours directement à un logiciel de publication assistée par ordinateur. Nous devons noter que ce mouvement inspiré des technologies du Web n’est pas si récent, Hachette ou O’Reilly Media en témoignent d’une façon singulière.
Nous nous concentrons sur la publication en tant qu’elle concerne le document, le livre, mais également des données disponibles de façon plus brutes. Getty Publications est en effet en mesure de proposer, en plus des formats déjà mentionnés, l’ensemble des prises de vues ou les jeux de données de description des objets de leurs catalogues. Des fichiers aux formats JPEG, CSV ou JSON des œuvres présentées viennent s’ajouter aux PDF, EPUB ou MOBI. Cela représente une opportunité importante pour les lecteurs et utilisateurs de ces publications : l’étude de mosaïques romaines peut s’appuyer sur la présentation d’œuvres contextualisées à travers un catalogue édité, mais aussi avec la description des différentes mosaïques sous un format exploitable comme un fichier JSON ou un tableur.
Dans le même esprit, nous pouvons mentionner la revue Distill présentée dans la partie 2 : chaque article, en plus d’être consultable en ligne, est également téléchargeable sous la forme d’un dépôt Git, et lisible localement à l’aide de programmes spécifiques. Ainsi les différents graphiques et diagrammes interactifs peuvent être étudiés et modifiés sur l’ordinateur de l’utilisateur sans impacter la version publique en ligne. Une publication ne se limite plus à un objet imprimé ou à un livre numérique qui sont des expressions organisées et délimitées de contenus, mais aussi étendues à des données moins éditorialisées.
3.2.4. De nouvelles contraintes ?
Nous proposons un nouveau modèle de publication, un système constitué de trois principes interdépendants : l’interopérabilité pour faciliter la circulation des données et la communication des outils entre eux ; la modularité, permise par l’interopérabilité, pour rendre chaque outil interchangeable et l’ensemble adaptable ; et la multiformité, permise par la modularité, ouvrant la perspective de formes très diverses d’une publication. Si le fondement de ces principes repose sur l’émancipation de fonctionnements établis sur des outils monolithiques et considérant la technologie dans sa dimension majoritairement solutionniste, nous devons néanmoins reconnaître les limites des hypothèses exposées dans cette partie. Se passer de logiciels de publication assistée par ordinateur et de traitement de texte implique, comme dans les cas exposés ici et dans la partie 2, le recours à des développements informatiques spécifiques et à l’utilisation de programmes open source ou libres. D’une dépendance à des logiciels spécifiques et dont le choix est souvent limité – depuis une dizaine d’années la mise en page est réalisée très majoritairement avec InDesign –, nous passons à une dépendance de programmes ouverts mais nombreux. La modularité d’un système doit permettre le changement d’un composant par un autre mais encore faut-il avoir les compétences pour choisir et intégrer ces nouvelles briques.
La chaîne de publication numérique de Getty Publications était par exemple constituée autour du générateur de site statique Middleman (Gardner, 2015), pour aujourd’hui utiliser un autre générateur de site statique, Hugo. La source des documents étant le langage de balisage léger Markdown et le langage de description YAML, deux formats interopérables, la transition a été possible. Les contraintes ne sont plus les mêmes, et la présence d’un développeur est nécessaire pour maintenir et faire évoluer un tel système. Les compétences requises sont nouvelles et permettent une indépendance toute relative.
Si nous devons constater que ce nouveau modèle fait apparaître de nouvelles contraintes, elles sont néanmoins d’une nature différente, ouvrant des perspectives en termes de formes, laissant l’utilisateur maître du workflow qu’il constitue, permettant une évolution vers d’autres possibilités numériques, et surtout appelant à une certaine diversité d’outils et d’approches dans le domaine de l’édition. Devenir chef d’orchestre d’un dispositif, et non plus opérateur ou surveillant (Simondon, 2012), implique d’acquérir une culture technique, avant même d’envisager de maîtriser des connaissances plus complexes comme la programmation. L’un des chantiers incontournables résultant de l’application de ces principes est la formation aux outils disponibles et la création d’interfaces facilitant certaines actions d’édition, comme le souligne l’un des membres de l’équipe du département numérique de Getty Publications (Gardner, 2017).
-
La communauté autour du logiciel libre de publication assistée par ordinateur Scribus en est un exemple, dont l’objectif était de remplacer le logiciel propriétaire Adobe InDesign. ↩